Intelligent Inference Scheduling with llm-d





The llm-d project lays out clear, “well-lit” paths for anyone to adopt the leading inference optimizations within their existing deployment framework - Kubernetes. These are tested approaches designed to make complex deployments easier and more efficient. In this post, we explore the first of these paths: intelligent inference scheduling. Unlike basic round-robin load balancing, this method takes the unique demands of LLMs into account, leading to better performance across the board: higher throughput, lower latency, and efficient use of resources.
Why Intelligent Inference Is Needed for LLM Inference
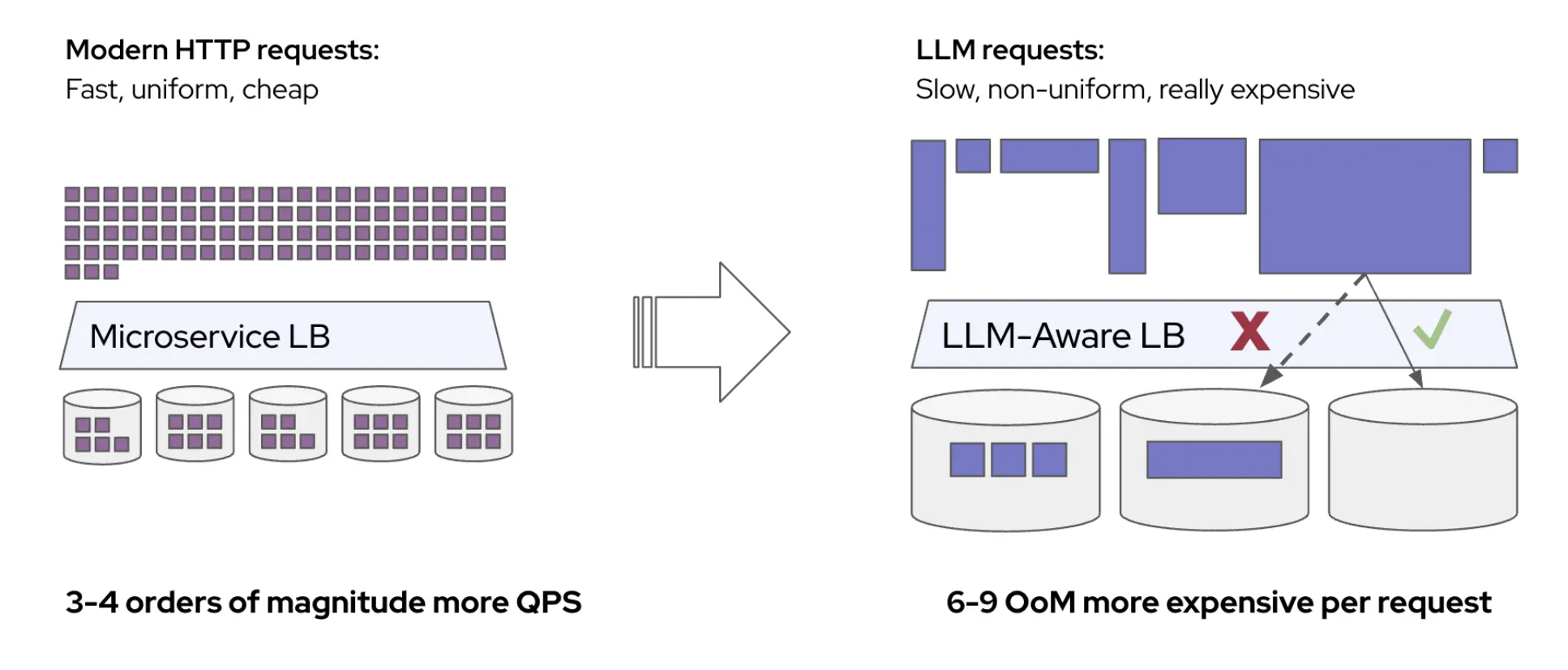
Deploying large language models (LLMs) on Kubernetes has become the norm, but LLM inference workloads behave very differently from standard microservices. Traditional patterns like uniform replicas paired with round-robin load balancing assume each request uses the same amount of resources and finishes in roughly the same time. In contrast, LLM requests can vary wildly in token count and compute needs, making simple load-spread strategies prone to bottlenecks and imbalanced traffic.